Tools
Caching Best Practices
Caching is the temporary storage of web data so that later requests for that data can be served faster. When you use caching, your application can respond to data requests with data in the cache instead of executing another request for the data from Rovi.
If your contract with Rovi allows you to cache data, caching can reduce both your data delivery time and your transaction costs. Caching can also help unify Rovi-provided data under your own domain if you are using a browser-based client that follows the same-origin policy.
This document describes best practices for using caching with the Rovi Cloud Services APIs. We cover the basics of using caching and how to design your Rovi Cloud Services calls to make the most of your caches.
Types of Caches
We recommend the use of both local and intermediate caches to cache Rovi data:
- A local cache is a cache that is located on the same box or device as your application.
- An intermediate cache is a cache that is located between your clients and Rovi Cloud Services.
Local Cache
- A local cache is a cache that is located on the same box or device as your application.
- We recommend making use of a local cache for each client in order to hold, and perhaps even prefetch, data for the customer. Using a local cache, you can ensure that whenever your customer reviews data they previously requested, the data can be displayed instantly without requiring another request back to the cloud.
- We recommend that you keep a local cache of all data immediately relevant to the end user.
- The local cache represents the best value to the customer, but local caches are often limited in size and so may not hold all of the data a customer might ask for. Because of this, we also recommend using an intermediate cache as described next.
Intermediate Caches
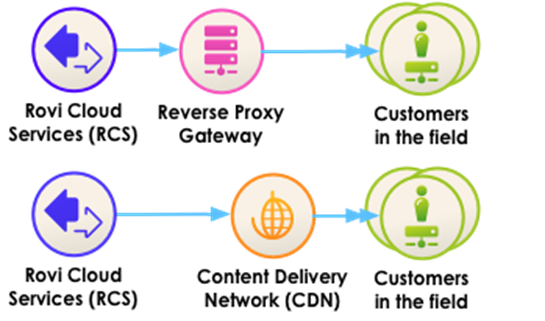
- In addition to local caches, we recommend using an intermediate cache between your clients and Rovi Cloud Services. There are typically two forms of intermediate caches you can use: Reverse Proxy Gateways and Content Delivery Networks.
Reverse Proxy Gateway Cache
- A reverse proxy gateway cache can take the form of a set of off-the-shelf HTTP caching servers (such as Squid, Apache, or Varnish) that clients call back through. The proxy cache mediates all communication between your customers and Rovi Cloud Services, and caches responses from Rovi Cloud Services. The proxy cache is shared across your customers, and so can serve previously requested data to all of your customers without needing to hit Rovi Cloud Services for your most commonly requested data.
- From a network topology perspective, you are routing clients through your proxy cache, which places your proxy cache location at the center of your clients' routes to obtain data from Rovi Cloud Services. This may work well if your cache is centrally located, but may pose additional latency if some of your customers are far from that location. You can, of course, set up multiple proxy locations, and route your clients to the nearest cache, but each proxy cache will then act as an independent cache.
- Using the proxy cache, you control how much infrastructure to deploy, and you don't have to pay a monthly fee (there are many open-source HTTP caching servers that run on Linux). A proxy cache can be as simple as a single server, or as complex as a tier of interconnected servers. If you do wish to employ more than one machine, we recommend a tiered approach of a single Alpha cache that is fronted by N independent Beta caches.
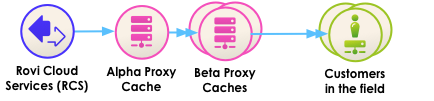
- An Alpha cache works as the primary cache: when any customer requests Rovi Cloud Services data, the data is added to the primary cache and becomes available to all other users. But a single Alpha cache may have trouble keeping up with load and represents a single point of failure. To mitigate this, place N Beta cache servers in front of the Alpha cache, and use a load balancer to distribute requests to the Betas. Client requests then go to one of the Betas, which in turn will go to the Alpha if the Beta does not have the content. Rovi Cloud Services will then be called only if the Alpha server does not have the content. Over time, all of the cached data in the Alpha will be promoted up to the Betas, and you will have a lot more redundancy in case one or more of your servers goes down.
Content Delivery Network Cache
- As an alternative to setting up your own proxy cache, you can pay a Content Delivery Network (CDN), such as Akamai or Limelight, to act as a proxy cache for you. This is known as "caching as a service." CDNs typically charge for the amount of traffic they proxy.
- The main benefit to using a CDN is that it edges out content close to your clients, which reduces the latency for your clients if they are geographically distributed. Generally speaking, your customers may get greater benefit from a CDN, but a CDN may cost more than standing up your own proxy cache.
Unifying Your Domain for HTML5 Applications
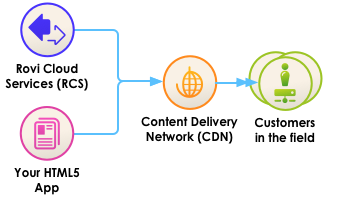
- Both forms of intermediate caches provide an additional benefit: they can redistribute Rovi Cloud Services data under your own domain. Why would you want to do that? Because browser-based HTML5 applications follow a same-origin policy: the HTML page and the JSON data received through AJAX calls must originate from the same domain. Since you can expose the cache under your domain, you can use the cache to unify Rovi data under your own domain. Very often, HTML5 applications make use of a CDN anyway, to accelerate the HTML, Javascript, and media portions of the application. Leveraging your CDN to also accelerate Rovi Cloud Services data solves all of those problems at once.
Cache Directives
When you set up a cache, you need to decide how to control the duration of cached data, that is, how long you return cached data before you need to refresh it. There are a couple of ways to do that: 1) by using the Cache-Control header fields returned in responses, and 2) by configuration settings in your cache software.
However you control the duration of cached data, the duration must meet the terms of your contract with Rovi.
Cache-Control Headers
- As described in the overview to this service, Rovi includes standard HTTP 1.1 Cache-Control header fields in API responses. These header fields represent our best estimate of how long you should store data in order to obtain the best trade-off between cache reuse and data freshness.
- By providing Cache-Control header fields, Rovi can optimize the Time To Live (TTL) directives of different content in order to maximize this trade-off. For example, if we know that the data for a particular response is unlikely to change, we can set a long TTL; while more volatile data may be given a shorter TTL.
- Cache-Control header fields give you a ready guideline for your caching. We will modify these header values over time as we update our caching algorithms, and we reserve the right to do that at any time.
- Note: Your use of Cache-Control header fields, like your use of caching in general, is subject to the terms of your contract with Rovi. Cache-Control header fields do not authorize any use of caching that is not permitted by the terms of your contract.
Managed Cache Configuration
- Alternatively, if your contract with Rovi permits caching, you can also choose to ignore the Cache-Control header fields and configure your cache so it caches content in a different manner, in accordance with your contract with Rovi. Exactly what right you have to cache, if any, is determined by your contract with Rovi.
- You may, for example, have the right to cache Rovi data for up to 12 hours. In this case, you can configure your caches to cache data for up to 12 hours, regardless of any cache control headers in the responses. Most caches, both local and in the cloud, allow you to configure the cache directives directly.
Preparing Your Caches
- There are a few things to consider up front to ensure that you will be able to make the most use of your local and shared caches. Some of these relate to how your caches are configured, while others relate to the expected traffic patterns of your clients.
Cache Configuration
- Here’s some advice about configuring your caches.
Pay Attention to Query String Parameters
- In general, you need to configure your cache to pay attention to query string parameters. Query string parameters are request parameters that come after the question mark in the URI and take the form of parameter=value, such as country=CA. The Rovi Cloud Services API passes most request parameters as query strings, so the cache needs to use those parameters to distinguish requests.
Ignore the Signature
- One exception, however, is the sig query string parameter. Your cache must ignore the sig parameter. This is the parameter that carries the time-sensitive API signature that authenticates your calls to Rovi Cloud Services. Because this signature is time-sensitive, it must be ignored or you will never have any cache hits in the shared cache from across your client pool.
- Once you ignore the signature, however, it does become possible for other systems to try to probe your cache for Rovi Cloud Services data using bogus signature values. But any time the request missed the cache, the request would fail when it reached Rovi Cloud Services. As such, the caller would be unable to trick your cache into obtaining new data on its behalf.
Do Cache Your API Key
- Although unlikely, the apikey query string parameter does theoretically open your cache to the possibility of being highjacked into storing data for another Rovi Could Services customer. The apikey parameter is the parameter that carries your public API key in your client requests. In theory, someone else who uses Rovi Cloud Services could route their calls through your cache to take advantage of it.
- To circumvent that possibility, however remote it may be, you should cache only requests that use your API key.
Retry 403 Over-Per-Second Responses
- There is one error message that both your local and intermediate cache should watch for. This is the error message from the Rovi API hosting service that tells you that the maximum number of requests you are contractually allowed during one second have already been received:
403 Account Over Queries Per Second Limit
- Because this error message indicates a temporary limit of one second, simply retrying the request from your intermediate cache gives you a faster way of resolving the problem than relaying the message back to the client to try again. We recommend using an exponential backoff algorithm for retrying these requests.
- In addition, we strongly recommend that this retry logic also be implemented by your client in case the intermediate cache is down or gives up, and the error message does make it back to your client.
- Other 403 error messages, such as Forbidden, should NOT be handled in the same way. Those error messages represent real problems that are not resolvable with a simple retry.
Sharp-Onset Traffic Spikes
- It sounds simple: When you have an intermediate cache, one client requests some data, the data gets added the cache, and so when the next group of clients request that same data, the data is already in the cache.
- But there is one situation that circumvents an intermediate cache: a large number of clients all making the same initial request at once. The response doesn’t make it into the cache because they all hit at once, so the requests all go to Rovi Cloud Services and perhaps hit your transaction-per-second limit.
- The solution is to employ logic that discourages a large number of clients from all making that initial request at the same time. This section describes two ways to do that.
Randomize Automated Download Times Across Clients
- One reason that traffic spikes can occur is synchronization of clients. If, for example, your client expects to download listings data every hour, it might be configured to download that data exactly on the hour. If that happens, every client you have will try to request their data at the top of the hour, which will create a sharp-onset traffic spike.
- You should take steps to ensure that your clients are as unsynchronized as possible. If you are downloading data asynchronously, we recommend finding ways to randomize the timing of your clients so that their requests are uniformly distributed.
Warm the Cache Before Spikes
- Another reason traffic spikes can occur is synchronization of humans. This commonly happens because an event such as a series finale or a sporting event is about to start.
- If you have reason to believe that people are creating sharp-onset traffic spikes, one possible mitigation is to warm your cache ahead of the spike by running a script to request the most-likely Rovi Cloud Services requests through your cache. That script does not have to live on your clients. That script can originate from anywhere, as long as it calls through the same cache as your clients.
Preparing Requests
The key to optimizing your caches, especially shared caches, is to design your client so that all clients use common URIs for common requests. Ideally, you want your clients in the field to use as few unique URIs as possible. Therefore you need to look carefully at how you construct your requests to Rovi Cloud Services so you encourage high cache hit rates through the URIs and traffic patterns you create.
Try to Constrain Variables
- The first step is to look carefully at the calls you will be making and to constrain as many parameters to as few values as possible. Ideally, you want most of the parameters on the call to have fixed values that are universally applicable to all of your clients. For those parameters that can't be fixed, try to limit them to as few values as possible.
- You will find some parameters have the same value for all calls. For example: apikey, format, and possibly country and language. You should ignore the sig parameter. The apikey and format parameters should each have a single value for all of your clients.
- This means that the actual hit rate for a particular call will be determined mainly by the combination of values in other parameters.
Create Requests the Same Way Every Time
- Naturally, you should make sure that your clients all create a URI in the same way when they are making the same request. Most caches will ignore the order of query string parameters, but keeping the same order may make the cache even more efficient.
- Some parameters accept multiple values. For these parameters, you should ensure that the same set of values appear in the same order every time.
- Avoid making a call that is a subset of a previous call. If the response data is in the cache, it would be better to get that data and use just the data you need. For example, if your client makes a name/info request that includes images, it is unnecessary to make another request without images. Just make the request with the images, even if the client sometimes ignores the images. That way the cache would be filled with the data and the subsequent request would find it in the cache.